
Google ショッピングにおいて、商品データに設定する title 属性(タイトル:商品名)をどのように構成するかは非常に重要な問題です。title 属性を適切に構成できるかによって検索語句と商品の関連性、クリック率、コンバージョン率などに大きく影響してきます。
一方で、title 属性に含めるべき情報やその順番というのは、その商品の属するカテゴリによって変わってきます。
つまり、商品の属するカテゴリ = google_product_category 属性(Google 商品カテゴリ)ごとに、title 属性に含めるべき要素や優先順位のパターン存在すると言えるでしょう。
では、google_product_category 属性として用意されているカテゴリ数はどのくらいあるのでしょうか?
正解は…… 5,595 カテゴリ(2025年5月6日現在)です。
ヒトが1カテゴリ分の構成を1分で作成できたとして、すべてのカテゴリを対応するのに 5,595 分。つまり 93.25 時間かかる計算です。到底ヒトが対応しきれる分量ではありません。
この作業をなんとか自動化できないかと考え、ChatGPT(GPT-4o)を使って全カテゴリの構成を自動設計してみました。本記事はその記録として残しておきます。
適切なタイトルの構成を設計するにあたっての課題
改めて、現在感じている課題をまとめておきます。
title 属性をどのように構成するかは、検索語句との関連性向上、クリック率、コンバージョン率など、さまざまな指標に大きな影響を与えます。一方で、仮説として google_product_category(Google 商品カテゴリ)の 5,595 カテゴリの数だけ、それぞれにベストプラクティスの構成が存在すると考えています。
しかし、これをヒトの手ですべてのカテゴリについて設計するのは現実的ではありません。属人性が高くなるだけでなく、一貫性の欠如にもつながりかねません。
そこで、ヒトの属人性に頼ることなく、一貫性を保ちながら google_product_category ごとの title 属性のベストプラクティスな構成案を自動的に設計できれば理想的だよね、というのが今回の課題です。
今回とったアプローチ
Google スプレッドシート & Gemini for Google Workspace
Google Workspace Business Standerd を契約しているので、まずは手軽に実装できそうなアプローチとして、Google スプレッドシート上で生成 AI を利用できる AI() 関数を利用し、手軽に実装できないか試してみました。
実装してみて分かったのですが、1 度に処理できるのが 200 セルなので、これを手動で 28 回対応する必要があります。また、プロンプトが悪かったのか推論が少し弱いのか分からないのですが、期待した出力が得られなかったということもあり、このアプローチは諦めました。
ChatGPT 4o & API & Python
カテゴリ数が 5,595 分の title 属性の構成を行うために、費用を掛けずに対応しようとすると、そのぶん手作業が増える、思ったような出力が得られるとは限らないといった課題が見えてきました。これはきちんと費用を掛けてシステムを作ってしまう方が、大きな費用対効果も得られると思い、API を使ってシステムを構築することに決めました。
僕は、Google Gemini、Chat-GPT、Claude の有料プランを使っています。なので、どの生成 AI のモデルを使うべきかを見定めるため、まずは特定の商品データと google_product_category について各生成 AI に同一のプロンプトを渡して、title 属性の構成案を出力してみたところ、結果的に推論が強めの ChatGPT 4o で構築した方が良い構成案を出力してくれたので、API に課金をして GPT 4o を使うシステムの構成にすることを決めます。
システムの構成は ChatGPT 4o に相談し、プログラミング言語の Python を使い、TSV (タブ区切り形式テキスト)で構成された google_product_category のタクソノミーをプログラムに渡し、各カテゴリーごとにプロンプトを使って title 属性の構成案を生成する仕組みにしました。プログラムのコードの生成ももちろん ChatGPT 4o でコーディングしてもらいました。
API の課金はトークン数(テキストデータを処理する際の最小単位の数)で決まるため、プロンプトや出力を日本語で行うと費用がかさんでしまいます。なので、プロンプトは英語、出力する title 属性のテキストは日本語にし、少しでもトークン数を節約するようにしました。この節約術も ChatGPT 4o と相談して決めています。
生成に利用してもらったプロンプトは下記です。
Google product category: {category}
For this category, identify the key attributes that customers would compare when choosing a product.
Propose the recommended order of attributes for the product title, arranged by importance.
Follow these best practices:
- Use as many of the 150 characters as possible.
- Place the most important details at the beginning.
- Include keywords such as product name, brand, and specific product details (like “maternity” or “waterproof”) if applicable.
- If some attributes are not relevant for this category, omit them.
IMPORTANT:
Output ONLY the attribute order in Japanese.
Do NOT include any explanations, reasons, or additional text.
Output example:
ブランド-商品タイプ-材質-サイズ-取り付け方式-色-型番日本語にすると下記。
Google 商品カテゴリ: {category}
このカテゴリにおいて、顧客が商品を選ぶ際に比較する主な属性を特定してください。
商品タイトルに含める属性の推奨順序を、重要度に基づいて提案してください。
次のベストプラクティスに従ってください:
- 可能な限り150文字を活用すること。
- 最も重要な情報をタイトルの先頭に配置すること。
- 商品名、ブランド、および「マタニティ」や「防水」などの特定の製品情報(該当する場合)を含めること。
- このカテゴリに関連しない属性は省略すること。
重要:
出力は属性の順序のみを日本語で記載してください。
説明、理由、その他のテキストは一切含めないこと。
出力例:
ブランド-商品タイプ-材質-サイズ-取り付け方式-色-型番ベストプラクティスというのは、Google Merchant Center ヘルプの title 属性のページに記載されているおすすめの方法を用いています。ヘルプページに記載されている説明は下記です。
おすすめの方法
ここでは、商品データの基本的な要件を満たしたうえで、さらに効果を上げるための最適化方法を紹介します。
タイトル [title] と構造化されたタイトル [structured_title] – Google Merchant Center ヘルプ https://support.google.com/merchants/answer/6324415?hl=ja#Bestpractices
- 上限の 150 文字(全角 75 文字)いっぱいまで使用します。タイトル [title] は、購入者の検索内容に商品を一致させるために使用されます。商品を定義する重要な情報を含めてください。
- 特に重要な情報を先頭に記載します。画面のサイズにもよりますが、通常、ユーザーに表示されるのはタイトルの最初の 70 文字(全角 35 文字)程度です。
- キーワードを使用します。キーワードは商品と購入者の検索内容の関連付けに役立ち、販売している商品を購入者が識別しやすくします。キーワードには次のようなタイプの商品情報を含めることができます。
- 商品名
- ブランド
- 商品分野に関する具体的な情報(ファッション関連商品であれば「マタニティ」、マスカラであれば「ウォータープルーフ」など)
- 外国語の名前やタイトルが広く使われている場合以外は、外国語の語句は使わないようにします。
- たとえば、「sushi」(寿司)という言葉は日本以外でも広く使われています。
- 外国語は対象言語の文字を使って表記します。たとえば、米国を対象とする場合は日本語の文字は使わないようにします。アクセント記号を含む文字(「Les Clés」など)は使用できます。
つまり、その商品カテゴリにおいてユーザーが着目する要素を類推するだけではなく、Google のおすすめも反映できるように指示をしています。このプロンプトも、前述のおすすめの説明を踏まえて ChatGPT 4o にトークンの最適化をしてもらいました。
プログラムのコードについては詳説を避けますが、最終的に下記のコードとなりました。長いので、もし興味がある方だけ見てみてください。
システム要件
| 要件 | 内容 |
|---|---|
| Python | バージョン 3.9〜3.11(3.10.x で動作確認済み) |
| pandas | 最新版(2.x系がおすすめ) |
| tqdm | 最新版 |
| openai | バージョン 1.0.0 以上(ChatCompletion.create 対応) |
入力データ(TSVファイル)
| ファイル | 内容 |
|---|---|
| google_product_category.tsv(または任意のTSV) | google_product_category 列(カテゴリ名) |
※ 初回実行では「title_attribute_order」と「status」は空欄または存在しなくてもOK。
※ 2回目以降は categories_with_titles.tsv か google_product_category.tsv など、前回処理済のファイルを使う。
カラム例:
| google_product_category | title_attribute_order | status |
|---|---|---|
| Animals & Pet Supplies | (空欄 or データ) | pending / completed |
import openai
import pandas as pd
from tqdm import tqdm
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
# === ご自身の OpenAI API キーをここに記入 ===
api_key = "YOUR_OPENAI_API_KEY"
client = openai.OpenAI(api_key=api_key)
MODEL = "gpt-4o"
# === 英語出力版プロンプト ===
PROMPT_TEMPLATE = """
Google product category: {category}
For this category, identify the key attributes that customers would compare when choosing a product.
Propose the recommended order of attributes for the product title, arranged by importance.
Follow these best practices:
- Use as many of the 150 characters as possible.
- Place the most important details at the beginning.
- Include keywords such as product name, brand, and specific product details (like “maternity” or “waterproof”) if applicable.
- If some attributes are not relevant for this category, omit them.
IMPORTANT:
Output ONLY the attribute order in English.
Do NOT include any explanations, reasons, or additional text.
Output example:
Brand-Product Type-Material-Size-Mounting Method-Color-Model Number
"""
# === ファイル名(読み込むデータ) ===
input_file = "google_product_category.tsv" # ★前回実行して生成された最新版TSV(ファイル名を変えるだけ)
# === データ読み込み ===
df = pd.read_csv(input_file, sep="\t", encoding="utf-8")
if "title_attribute_order" not in df.columns:
df["title_attribute_order"] = ""
# === status列の更新関数 ===
def update_status(row):
val = str(row["title_attribute_order"]).strip()
if val == "" or pd.isna(val):
return "pending"
if val.startswith("Unhandled error") or val.startswith("Error after"):
return "pending"
return "completed"
# === status列(無ければ作成&更新) ===
df["status"] = df.apply(update_status, axis=1)
# === 実行対象行(pending)抽出 ===
pending_rows = df[df["status"] == "pending"]
print(f"\n【今回の実行対象:{len(pending_rows)}件】\n")
for i, (idx, row) in enumerate(pending_rows.iterrows()):
if i < 20:
print(f"{idx}: {row['google_product_category']}")
elif i == 20:
print("(以降省略...)")
pending_rows.to_csv("今回実行対象カテゴリ一覧.tsv", sep="\t", index=False, encoding="utf-8-sig")
print("\n→ '今回実行対象カテゴリ一覧.tsv' に出力しました。\n")
# === 差分レポート(開始時点) ===
df[["google_product_category", "title_attribute_order", "status"]].to_csv(
"差分レポート_今回の状況.tsv", sep="\t", index=False, encoding="utf-8-sig"
)
# === 重複カテゴリチェック ===
completed_categories = df[df["status"] == "completed"]["google_product_category"].unique()
pending_categories = pending_rows["google_product_category"].unique()
overlap = set(completed_categories).intersection(set(pending_categories))
print(f"✅ pending と completed の重複カテゴリ数:{len(overlap)}")
if overlap:
print("重複カテゴリ(最大10件表示):")
for c in list(overlap)[:10]:
print("-", c)
pd.DataFrame({"duplicate_categories": list(overlap)}).to_csv(
"重複カテゴリ一覧.tsv", sep="\t", index=False, encoding="utf-8-sig"
)
print("→ 重複カテゴリ一覧.tsv を出力しました。\n")
# === ChatGPT API 呼び出し関数(リトライ付き) ===
def get_title_structure(category, max_retries=3):
prompt = PROMPT_TEMPLATE.format(category=category)
retries = 0
last_exception = None
while retries < max_retries:
try:
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a product title structuring assistant."},
{"role": "user", "content": prompt}
],
temperature=0.2
)
full_text = response.choices[0].message.content.strip()
first_line = full_text.split("\n")[0].strip()
return first_line
except Exception as e:
last_exception = e
retries += 1
print(f"エラー({category})リトライ {retries}/{max_retries}: {str(e)}")
if "rate limit" in str(e).lower() or "429" in str(e):
time.sleep(30)
else:
time.sleep(5)
return f"Error after {max_retries} retries: {str(last_exception) if last_exception else 'Unknown error'}"
# === 並列実行 ===
THREADS = 10
with ThreadPoolExecutor(max_workers=THREADS) as executor:
futures = {
executor.submit(get_title_structure, row["google_product_category"]): idx
for idx, row in pending_rows.iterrows()
}
for future in tqdm(as_completed(futures), total=len(futures)):
idx = futures[future]
try:
result = future.result()
except Exception as exc:
result = f"Unhandled error: {str(exc)}"
df.at[idx, "title_attribute_order"] = result
# === 処理後 status 再更新 ===
df["status"] = df.apply(update_status, axis=1)
# === 進捗レポート ===
total = len(df)
completed = (df["status"] == "completed").sum()
errors = total - completed
success_rate = completed / total * 100 if total > 0 else 0
print("\n【進捗レポート】")
print(f"全体カテゴリ数:{total}")
print(f"成功件数:{completed}")
print(f"失敗または未処理件数:{errors}")
print(f"成功率:{success_rate:.2f}%")
# === 差分レポート(実行後) ===
df[["google_product_category", "title_attribute_order", "status"]].to_csv(
"差分レポート_今回の状況(実行後).tsv", sep="\t", index=False, encoding="utf-8-sig"
)
print("\n→ 差分レポート(実行後)を '差分レポート_今回の状況(実行後).tsv' に出力しました。")
# === 最終保存(次回実行用) ===
df.to_csv("categories_with_titles.tsv", sep="\t", index=False, encoding="utf-8-sig")
print("\n完了:categories_with_titles.tsv を出力しました。")システムで処理が完了するのにかかった時間と費用
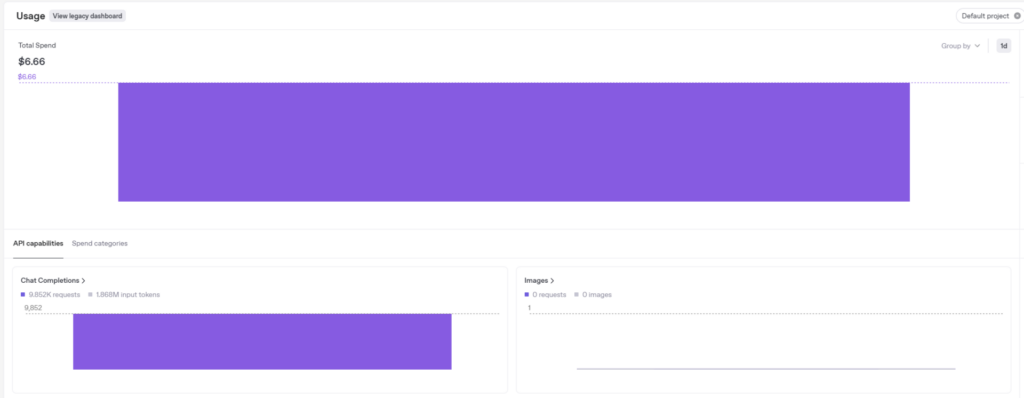
このプログラムによって、5,595 カテゴリーすべてに対して title 属性案を構成するまでにかかった処理時間は約 1 時間ほど。
かかった費用は $6.66 なのですが、初期にアウトプットされたプログラムでは出力が不十分で、1000 カテゴリ単位で何回かテストしていた時の金額も含まれているため、最終版のコードを使って処理した分だけで言うと $4 ~ $5 くらいの金額かなと思います。ChatGPT 4o と進めていた試算では $10 ~ $15 くらいを見込んでいたので、だいぶお安く済みました。
出力された title 属性の構成案の検証
google_product_category のタクソノミーに対して、出力された title 属性を並べてみると次のようになりました。
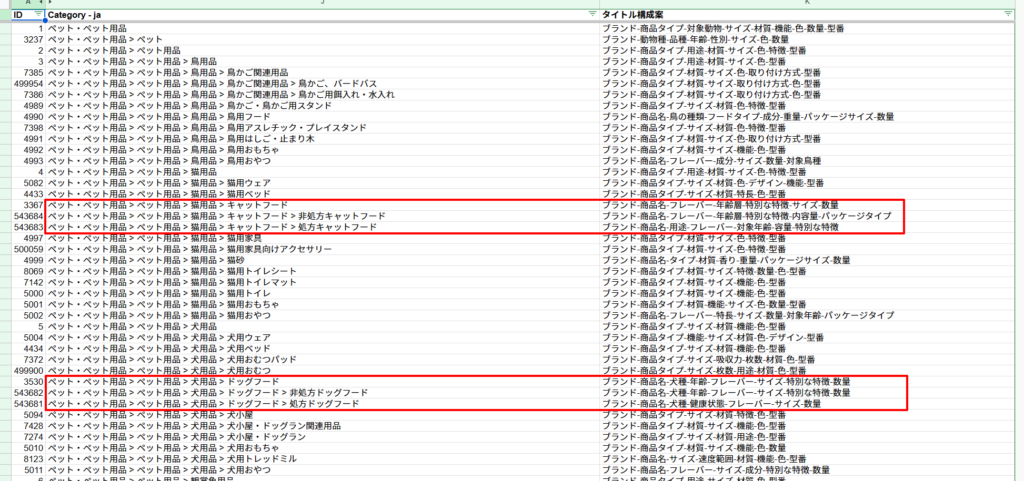
赤枠で囲ったキャットフードやドッグフードを見てみると、ペット・ペット用品 > ペット用品 > 猫用品 > キャットフード ならば title 属性の構成案は ブランド-商品名-フレーバー-年齢層-特別な特徴-サイズ-数量 という案が生成されたということになります。
フレーバーつまり何味か?というとても重要な情報が上位(先頭に近い方)に配置されていることが分かります。また、キャットフードやドッグフードなどの種類ごとにタイトル構成案が微妙に異なっているのが分かります。犬用は犬種も含まれているのも見てとれますね(猫用は猫種で検索しない?)。
この title 属性の構成案は必ずしも正解ではなく、あくまで推論ベースで仮説だてした結果の内容なので、この通りに title 属性を修正する必要はないですが、修正方針を決めるのにはすごく役に立つものにはなりそうです。
まとめと今後の活用
Google ショッピングに限らずですが、このような商品データの最適化は何を伝えるか?だけではなく何をどの順番で伝えるか?も考慮するべき視点だと考えます。
しかしながら、google_product_category に存在するカテゴリだけで 5,595 あり、これをすべてヒトの手でベストプラクティスを考えることはかなり難しいです。そこで、推論モデルが強い生成 AI を活用することで、ある程度ヒトが行うべき作業の一次対応を機械で行う仕組みを構築することができました。
今後は、実際に生成された title 属性の構成案のパフォーマンスがどのように変化するかのウォッチと、必要に応じて特定のカテゴリの構成の精査を行っていければと考えています。
恐らくこの程度の機能であれば、Google Merchant Center でも実装できてしまうと思うので、将来的にはこのシステムは役に立たなくなる可能性もあります。ですが、それまでの間、何もせずに待つと言うよりは、AI の力を借りて、できるだけ属人性に頼らず一貫性を持った出力ができるシステムの構築をしてみるのもよいと思いました。
生成 AI の API を使ったシステムの構築は今回が初めてですが、また何かアイディアが浮かんだら自由研究として今後も取り組んでみようと思います。