自分のサイトに来ているアクセスの中に、人間ではなさそうなものが大量に混じっていました。しかも、その多くは、知らない国や見たこともないクローラーからのアクセス。サーバーに届くリクエストを追って、はじめて気づいたことでした。
最近、森野誠之さんの「毎日堂」に攻城団の河野武さんが出ていた回を拝見しました。
「アクセス数自体は4倍以上に増え、その中で人間ではないアクセスが、人間によるアクセスの3倍以上あった」という話で、河野さんは「一番ひどい時はアクセスの80%がボットだった」とまでおっしゃっていました。しかも、それが2026年4月にいきなりドカンと来た、と。
当社でもボットアクセスには悩まされておりまして、2026年の1月頃からこの問題の分析と対応を続けてきました。
当社のサイトでは、広告主向け Google タグゲートウェイを利用する目的で、Cloudflare(無料版)を利用しています(その時の記事は下記にて)。
Cloudflare はサイトの高速化や安全性を高めるプロキシの役割も持っており、当社サイトの独自ドメインにアクセスする場合は、基本的に Cloudflare のサーバーを通る構成にしているため、Cloudflare 上でボットアクセスを観察、Cloudflare の無料セキュリティ機能を使って、できる範囲で対処しているという状況です。

毎日堂マーケティングラジオでもトピックとして扱われているとおり、この話題が注目を浴び始めてきているので、筆者のこれまでやってきたことをこの記事にまとめてみました。
本記事は、特定のサイトの設定値や具体的な遮断条件を意図的に伏せています。攻撃側へのヒントになりうるため、という河野さんの指摘にならったものです。考え方の共有として読んでいただければ幸いです。
2026年1月の異変から、半分まで削るまで
きっかけは、WordPress に入れていた Limit Login Attempts Reloaded(ログイン試行回数を制限するプラグイン)からの通知でした。2026年の1月頃から、ログイン試行をブロックしたという通知メールが、妙に増えてきた所から始まります。
第三者によるログインの試行とエラーの記録は前々から検知できていたのですが、以前はあっても1日に数回程度でした。しかし、2026年に入ってから1日に数百回のログインエラーのログが確認できるなど、ちょっとこれまでとは様相が変わってきたということが発端になっています。
おかしいなと思い Cloudflare の管理画面を開き、「セキュリティ」の「Analytics」を眺めてみたところ、見たことのない国からのアクセスや、知らないクローラーからのアクセスが大量に来ていることに気づきました。そこから気になって、少しずつ対策を進めていったという流れです。
筆者は Yuwai のコーポレートサイトのほかに、検証用の小規模な個人サイトも、同じレンタルサーバー上で運用しています。本番のクライアント案件でいきなり試せないものを検証する実験場で、Cloudflare も入れてあります。
普段からこういう画面を覗く環境があったのが、今回は早めの気づきにつながりました。検証用の実験場のつもりが、図らずもボットの実態がよく見える観測所にもなっていた、という具合です。
下のグラフは、サーバーの利用統計の月次推移です(数値はコーポレートサイトと検証用サイトの合計)。冬場をピークに、Hits が段階的に下がっているのが見て取れると思います。
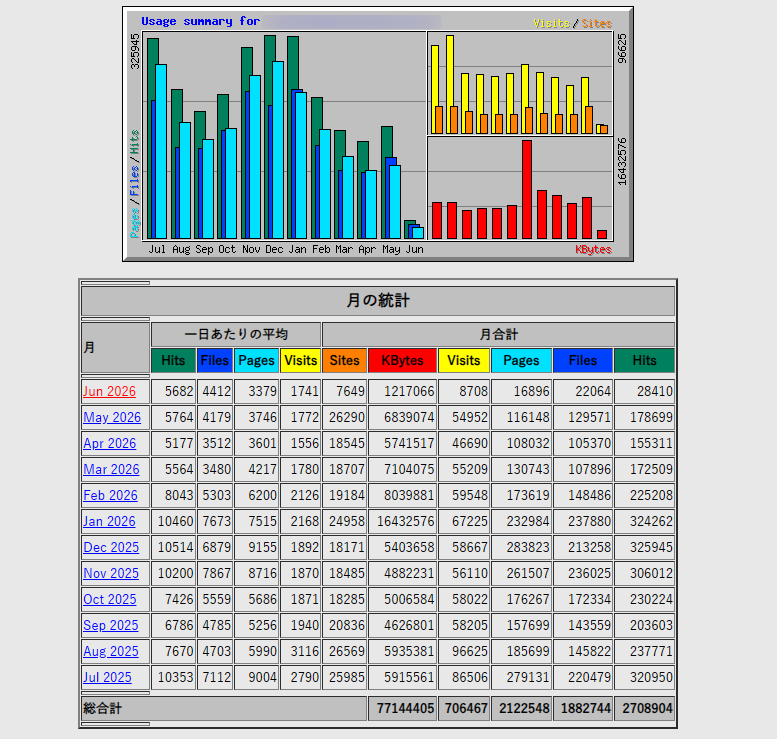
ひとつ正直に補足すると、この下がり方には「アクセス自体の季節変動・減少」も混じっている可能性があり、グラフだけでは「ボットを防いだ成果」と言い切れません。ですが、Google アナリティクス(以下、GA4)を見る限りではこの対応前後で大きなセッション数(特に direct や referral に分類されるもの)に大幅な減少はみられませんでした。
GA4 のレポートに影響を与えるようなボットアクセスは、そもそも少なかったであろう中で、不正ログインやスクレイピングなど、サーバーに負荷がかかるようなボットアクセスは、大幅に減らせている可能性が高いと見ています。
最終的には、サーバーに届く無駄なアクセスを生のアクセスログベースで半分近くまで減らせています。冒頭で触れた河野さんの「4月にドカンと来た」という話は、まさにこの数ヶ月の出来事の内容と重なります。自分だけの問題ではなく、業界全体で起きているパラダイムシフトなのでしょう。本記事は、その実体験のメモです。
GA4 だけ見ていても気づけない
まず大事なのは、この問題は GA4 だけ見ていても気づけないということです。
当社の場合は、幸いにも GA4 への影響はほとんどなかったようにみえますが、動画の中で河野さんがおっしゃるように GA4 のレポートへ影響を及ぼすこともあるようです。
また、河野さんも動画の中でおっしゃっていましたが、GA4 は既知のボットやスパイダーを自動的に除外する仕組みを持っています。けれど、いま増えているのは「普通のブラウザのふりをした」アクセスです。ユーザーエージェントは一般的な Chrome や Safari を名乗り、見た目には人間と区別がつきません。だから GA4 のページビューにそのまま紛れ込み、むしろ「アクセス増えてラッキー」と勘違いしてしまいます。
正体を掴むには、アナリティクスの画面だけでなく、サーバーのアクセスログと Cloudflare のファイアウォールイベントのログを突き合わせるしかありません。先ほどの内訳も、そこまで深掘りして初めて見えてきたものです。GA4 の綺麗な折れ線グラフの裏で、サーバーはまったく別の景色を見ているわけです。
出所不明なクローラーの見分け方
では、どうやって「人間ではないアクセス」を見分けるか。今回いくつかの手がかりが役に立ちました。
ひとつは Cloudflare のボット対策機能の活用です。AI 学習クローラーをクローラー単位でブロックできる機能があり、管理画面のリストから「これは通す/これは弾く」を選べます。
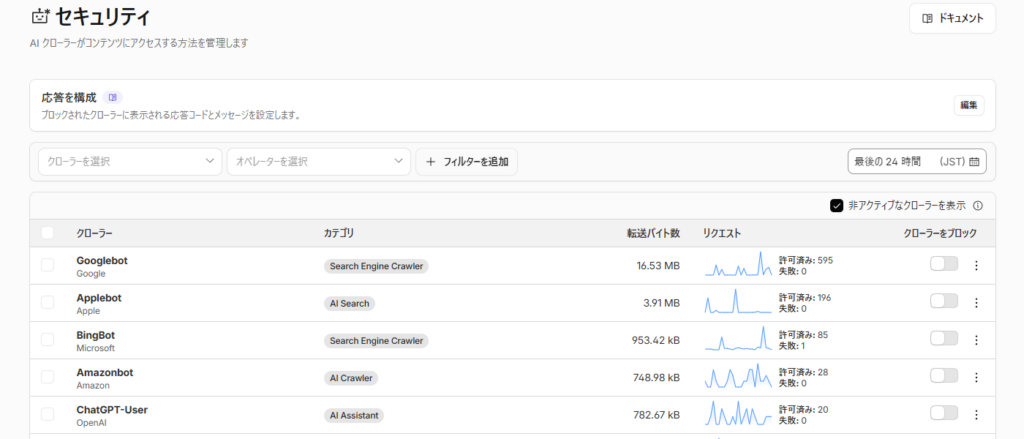
ChatGPT Bot や ClaudeBot のような名乗りのあるクローラーは、ここで素直に扱えます。筆者はもともとオフにしていましたが、まずはここを触ってみるのが入口としては分かりやすいと思います。
ただし、同じ Cloudflare の AI ラビリンス(AI Labyrinth:不正クローラーをダミーのリンク迷路に誘導する機能)は、入れてみて結局オフにしました。便利そうに見えたのですが、Slack やはてなブックマークのような、記事のプレビューを取りに来る良性のアクセスまで巻き込んでしまうケースがあったからです。全部入れれば安心、というものではありませんでした。
そして本丸が、ユーザーエージェントでは判別できないボットです。河野さんも「ユーザーエージェントだけでは人間のブラウザか分からない」とおっしゃっていましたが、まさにその通りで、ここは別の角度から攻める必要があります。
筆者が手がかりにしたのは 発信元の ASN(ネットワーク事業者) でした。データセンター(クラウド/VPS事業者)から来ているのにフルブラウザのユーザーエージェントを名乗っているなら、通常の訪問者である可能性はかなり低いと見ました。自宅やスマホからデータセンター経由でブラウジングする人は、基本的にいないからです。
ブラウザの偽装はできても、「どのネットワークから出てきたか」は偽装しにくい。完全な決め手ではありませんが、判断の手がかりとしてはかなり有効でした。
ブロックとマネージドチャレンジの使い分け
特定できたら、次は対処です。筆者は大きく2段階で考えました。
完全に黒なものはブロック。グレーなものはマネージドチャレンジ。 この使い分けがポイントでした。
通常の訪問者や正規の検索ボットが来る可能性が低い、明らかな問題ネットワーク(特定のデータセンター系 ASN)は、迷わずブロックでよいと思います。一方、「怪しいが正規アクセスも混じりうる」ものは、いきなり遮断せずマネージドチャレンジにかけます。
多くの通常ブラウザは大きな負担なく通過でき、単純な自動化ボットは止まりやすくなります。誤って正規ユーザーを締め出すリスクを下げつつ、機械的なアクセスを減らすための中間的な対処として使っています。

ただし、マネージドチャレンジも完璧ではありません。最近は、ブラウザを自動操作する AI エージェント(Claude や OpenAI の Chrome 拡張など)が増えています。
これらは個人のパソコン上で本物のブラウザを「正当に」動かしているため、チャレンジを人間と同じように突破してしまいます。河野さんも動画の中で、こうした自動運転ブラウザは「自分が使っているのと AI が使っているのとで全く区別がつかない」と指摘していました。チャレンジは「素朴な自動化ボット」には有効ですが、本物のブラウザを使って動く相手には通用しない。万能の壁ではなく、あくまで一枚目のフィルター、という前提で使っています。
逆に、安易に全体へかけると自分が痛い目を見る機能もありました。レート制限がそれです。
一定時間に一定回数を超えるアクセスを弾く設定を入れたところ、自分が WordPress の管理画面で作業していて、あっという間に制限に達してブロックされてしまいました。
画像をまとめてアップロードしたり、編集画面を行き来したりすると、人間でも普通に回数を超えてしまうのです。結局これは止めています。レート制限は対象や閾値をよほど慎重に設計しないと、運用者自身が最初の犠牲者になりかねません。
WordPress のログイン画面は手厚く
もうひとつ、特に検証用サイトの方で効いているのが WordPress のログイン画面を手厚く守ることです。
ログイン総当たり攻撃は、世界中の踏み台から毎日のように飛んできます。
ここは記事が読まれる以上に深刻で、一度でも突破されればサイトごと乗っ取られてしまいます。なので、ログイン画面に対しては Cloudflare のマネージドチャレンジをかけ、さらにログインフォーム自体に Turnstile(Cloudflare の CAPTCHA 代替)を置き、加えて WordPress 側で Limit Login Attempts Reloaded を併用しています。
冒頭で「通知が増えてきた」と書いたのが、まさにこのプラグインです。最初の警報を鳴らしてくれた道具を、そのまま防御の一枚に組み込んでいる形です。この三つを重ねると、ログイン試行の多くを手前またはフォーム段階で止められます。実際、ログイン失敗のカウントが見事にゼロで安定するようになりました。
Cloudflare のような CDN を使っていない場合は?
ここまで Cloudflare 前提で書いてきましたが、Cloudflare を導入していないサイトでも、できることはあります。むしろ出発点は同じで、まずは「自分のサイトに何が来ているかを知る」ことです。
把握の手段はシンプルです。レンタルサーバーのコントロールパネルから生のアクセスログを取得して眺める。サーバーの CPU や転送量のグラフに不自然なスパイクがないか見る。そして GA4 の数字(比較的人間寄り)とサーバーログの数字(全部込み)を突き合わせ、その乖離分がボットだと当たりをつける。これだけでも、河野さんの言う「サーバーを見ないと分からない」世界に一歩入れます。
対策も、手前から順にあります。まず robots.txt で行儀のいいクローラーに意思表示する(無断ボットは無視するので過信は禁物ですが)。次に .htaccess で、特定のユーザーエージェントやデータセンターの IP アドレス帯をブロックする。WordPress ならセキュリティプラグインで、ログイン試行制限やファイアウォール、不審な IP アドレスの遮断までまかなえます。レンタルサーバー標準の WAF 機能があれば、それを利用するだけで定型的なスキャンはある程度弾けるケースもあるでしょう。
そして何より、今なら生成 AI に伴走してもらえます。河野さん自身、動画の中で「AI を持って AI を制す」と、対策方法を AI に相談しながらひと月で対処したと話していました。ログを貼って「このアクセスは怪しいか」「.htaccess でこの ASN を弾くにはどう書くか」と聞けば、サーバー運用の専門家でなくても、かなりのところまで踏み込めます。完璧でなくていいのです。まず手を動かすことが、何より効きます。
ただし、.htaccess もプラグインも「リクエストがサーバーに届いてから」弾く方式です。河野さんが言う「同時に大量のアクセスが来てサーバーが悲鳴を上げる」状況だと、届いてから弾くのでは負荷を防ぎきれないことがあります。
Cloudflare のような CDN の利点は、サーバーに届く手前で弾けること。だから、余裕があれば CDN を噛ませると、対処が一段ラクになります。
直接アクセスという裏口を塞ぐ
CDN を入れても、オリジンサーバー(大元のレンタルサーバー)の IP アドレスが知られていると、CDN を素通りして直接攻撃される余地が残ります。CDN が手前で弾けるのは、あくまで「すべてのアクセスが CDN を通ってくる」前提があってこそです。
レンタルサーバーには初期ドメイン(〇〇.example.com のようなもの)も割り当てられていて、そこが裏口になりがちです。そこで筆者は、.htaccess で Cloudflare の IP アドレスの範囲以外からのアクセスを拒否し、CDN を通らない直接アクセスを塞いでいます。これをやっておかないと、せっかく間に CDN を挟んでも裏口が開いたままになってしまいます。
どれくらい効いたのか
今回オリジンサーバーへ届く無駄なアクセスが減ったのは、CDN でのキャッシュ、ボット遮断、そしてこの直アクセス封鎖と、複数の対策が重なった結果です。どれがどれだけ効いたかを厳密に切り分けられるほどのログは手元に残っていないので、内訳を断定はできません。
ただ、ひとつ手がかりになったのが GA4 の数字でした。
繰り返しになりますが、Webalizer(レンタルサーバーが提供する統計情報ツール)上のオリジンサーバー到達 Hits は明らかに減っているのに、GA4 のセッション数(特に direct や referral)は大きく減っていなかったのです。
キャッシュに関する設定は以前から変えていないので、この差は「当社のサイトではボットアクセスによる、ページビューの水増し被害はあまり受けておらず、GA4 には現れない種類のアクセス(不正ログインの試行やスクレイピングなど)を多く防ぐことができた」と読むのが自然だと思っています。GA4 の数字が減っていないことが、かえって「ページビューの水増しやその影響が目立つほどのものではなかった」証拠になっている、という少し逆説的な結果でした。
それでも「完全には防げない」
ここまで書いておいて何ですが、公開しているサイトを、出所不明なクローラーから完全に守ることはできません。これは正直に書いておきたいところです。
公開ページは人間のブラウザに見せるために存在します。そして最も賢いボットは、本物の Chrome と見分けがつきません。区別できないものは止められない。完全遮断を追えば追うほど、正規の読者や検索エンジンを巻き込むコストが跳ね上がっていきます。
河野さんも動画の中で、対策のノウハウを細かく公開できないジレンマを語っていました。「1分間に10回で弾いていると言えば、じゃあ9回ならいいんだなとヒントを与えてしまう」と。まったく同感で、だから本記事でも具体的な閾値や ASN のリストは伏せています。そして対策はいたちごっこです。止めても止めても新しいのが来ます。河野さんが手動のブラックリストを自動化したように、運用し続ける前提で組むしかありません。
達成できるのは「完全遮断」ではなく、「割に合わなくさせて、負荷とノイズを実用的な水準まで下げる」ことだと思います。筆者のサイトも、それでサーバーに届く無駄を半分近く減らすことができました。今のところ、それで十分だと考えています。
とはいえ、全部拒みたいわけでもない
最後に、デジタルマーケティングの支援を生業にしている立場として、ひとつ付け加えさせてください。
「不明なクローラーは全部弾きたい」という気持ちは正直あります。一方で、Web 上で情報発信する立場としては、AI 検索や AI アシスタントに 自分のコンテンツを見つけてもらい、推薦してほしい とも思っています。この二つは、よく考えると矛盾しています。
クローラーを片っ端から弾く網を粗く張ると、今は「不明」でも、将来あなたの記事を世界に届けてくれるかもしれない新しい AI クローラーまで、気づかぬうちに締め出してしまいます。今日の招かれざる客が、明日の流入源かもしれないのです。
ですから筆者は、「全部拒否」ではなく「明らかに無価値・有害なものだけ弾き、無害な正体不明は泳がせてログに記録する」という、選別的な構えを取っています。
AI に読ませたいのに、無断収集は拒みたい。この綱引きの中で、どこに線を引くか。正解はまだ誰も持っていないと思いますが、少なくとも「全部ブロック」が答えではないことだけは、はっきりしていると感じています。